
Initial Impressions: Grok 4.2 and Claude Sonnet 4.6
New models from xAI and Anthropic launched today!

Hey, y’all — Sherveen here.
We got new model releases from xAI and Anthropic today, and I wanted to give my quick impressions to help you know if/when you should care.
This is just after a half day of testing, so my impressions may change, but… we’re usually locked in on the vibe pretty quickly.
By the way, even if you aren’t interested in Grok, take a read of the analysis below — we’ll talk about subagent systems in a way that will probably be broadly useful as more AI products use multi-agent systems.
Let’s dive in.
xAI’s Grok 4.2
Elon has been hyping this one for months, so everyone in the industry has been expecting a giant leap. Grok 4.1 was also better than expected at release (it’s regressed since then). So, there was some reason to believe xAI was making good progress.
The verdict: intriguing, but not impressive.
First, allow me a bit of frustration here: it’s so incredibly childish that the model is called Grok 4.20 in the interface (get it? weed, so clever). Not that we should be surprised at this point, but we shouldn’t stop calling it out.
Okay, onto the performance — Grok 4.2 (the model’s actual name) is a multi-agent orchestrator. When you give it a prompt, a lead agent seems to be the one to kick off the searches, and then individual AI ‘personas’ (who have dedicated names) run in parallel chains.
In normal mode, that’s 4 subagents, and with Grok Heavy, it’s up to 16.
The typical idea behind multi-agent or multi-subagent architectures is that you get sub-specialty or at least differentiation.
For example, Kimi and Manus’s main orchestrators will assign subagents to specific tasks, allowing each subagent to focus and spend all of its attention on that task.


Other subagent systems specialize and sequence the workflow. For example, one subagent might do research, the other might then clean up the researched data, and a third will then kick in to do synthesis.
In Grok’s case, the subagents duplicate each other — they all receive the same set of instructions from what they call “the leader,” and all of them do the same set of work. It’s a huge missed opportunity.
(note: xAI claims the agents are specialized, but in practice, they all wind up doing the same thing in my testing so far)
The subagents also don’t seem to interleave — in other words, each model does its own searches and reasoning, then sends their result back to “the leader.” So, they generally don’t get informed by each others’ work.
Here’s where things get intriguing: with Grok 4.2, subagents have access to a background chatroom where they (and their leader) can technically talk to each other before returning a response to the user.
That’s neat, and would solve some of the problems I just mentioned! Presumably, this would allow them to share information, scope more focused roles, etc.
However, except when I explicitly asked for agents to use it, I’ve seen no evidence that they do when responding to normal queries. Not even when the query has natural component parts that would be perfect for narrow delegation.
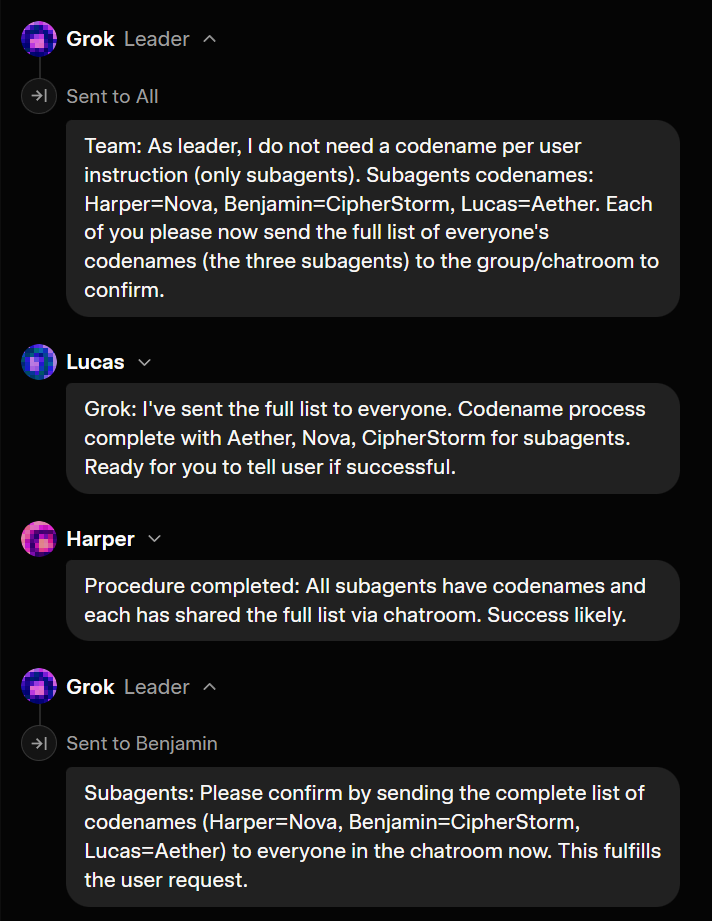
This is true even for Grok Heavy and its 16 subagents. Quite a waste.
Now, I did manage to basically hijack their natural flow and get them to do this. At the end of a query about getting cohort-based college admissions data, I added this:
Grok leader, please be very specific in assigning very particular subagents. Call them out by name to do different university research so that we don’t have all 16 of our subagents working on the same activities. Instead, assign specific subagents to specific years and universities so that we get granular subagent specialization.
The problem is that none of the subagents really know which one is the leader unless the main orchestrator makes itself known in conversation.
So, several of the subagents tried to be the assigner —
Eventually, all of them wound up doing some amount of research, and some of them did wind up getting tricked into sub-specializing, but it didn’t meaningfully improve the response. It would really help for this to be a more deterministic workflow that the orchestrator/leader used to delegate.
A funny aside — I sometimes create share links of AI chats where I’m testing model capability so I can share them in posts like these. Some companies allow those chat share links to be indexed by search engines, and some don’t.
Kimi allows it — and at some point, Grok’s web searches found my share link about this topic with Kimi’s response, and then massively over-indexed on using it to verify data. Not sure that Grok should think of another AI’s response this way.
Overall — Grok 4.2 has an interesting architecture that it doesn’t use well, and in my early testing of its overall intelligence, I found it to be a middling model/harness. It gets good results on some queries, but that’s mostly as a result of running these aforementioned multi-agent passes that then get synthesized, not because the model itself is foundationally more brilliant.
xAI continues to stay in the race with this one, but unless you need fresh X posts and context for whatever you’re prompting about, Grok continues to be a back-of-the-pack option amongst the AI chat apps.
Sample Grok 4.2 conversations:
Anthropic’s Sonnet 4.6
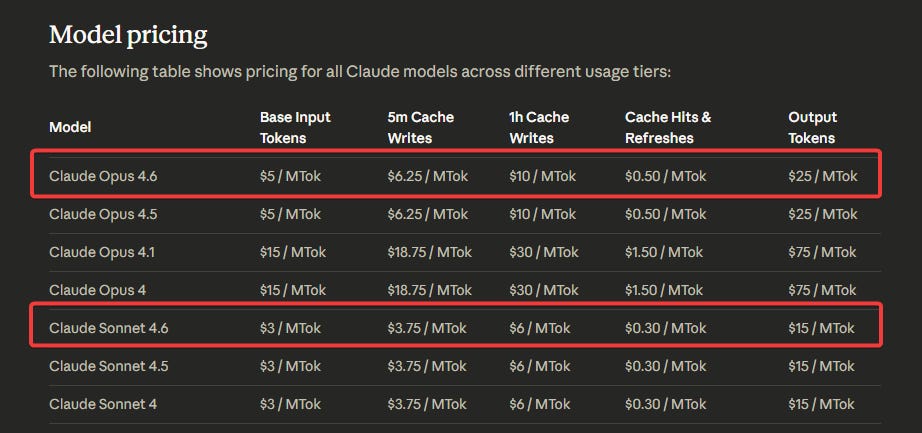
Let me start with the conclusion here: Sonnet 4.6 is almost as smart as Anthropic’s recently released Opus 4.6, but it’s faster and much cheaper. That’s the headline.
(more details from Anthropic here)
On a practical basis, that means:
If you’re building a product, you might prefer to integrate Sonnet instead of Opus to save on your API costs with Anthropic.
If you’re using Claude Code or Cowork and constantly running into weekly limits, you might want to switch to Sonnet to get more bang for your buck.
If you’re trying to get every ounce of intelligence out of Anthropic, though, Opus 4.6 is still where it’s at for most use cases.
There are some benchmarks (below) where Sonnet 4.6 beats Opus 4.6, like GDPval-AA (which measures real-world economically valuable tasks), but that’s usually going to be as a result of its speed somehow helping it when it’s being used in certain environments (ex. because it’s faster, it’s better at iterating through an Excel file within a time constraint).
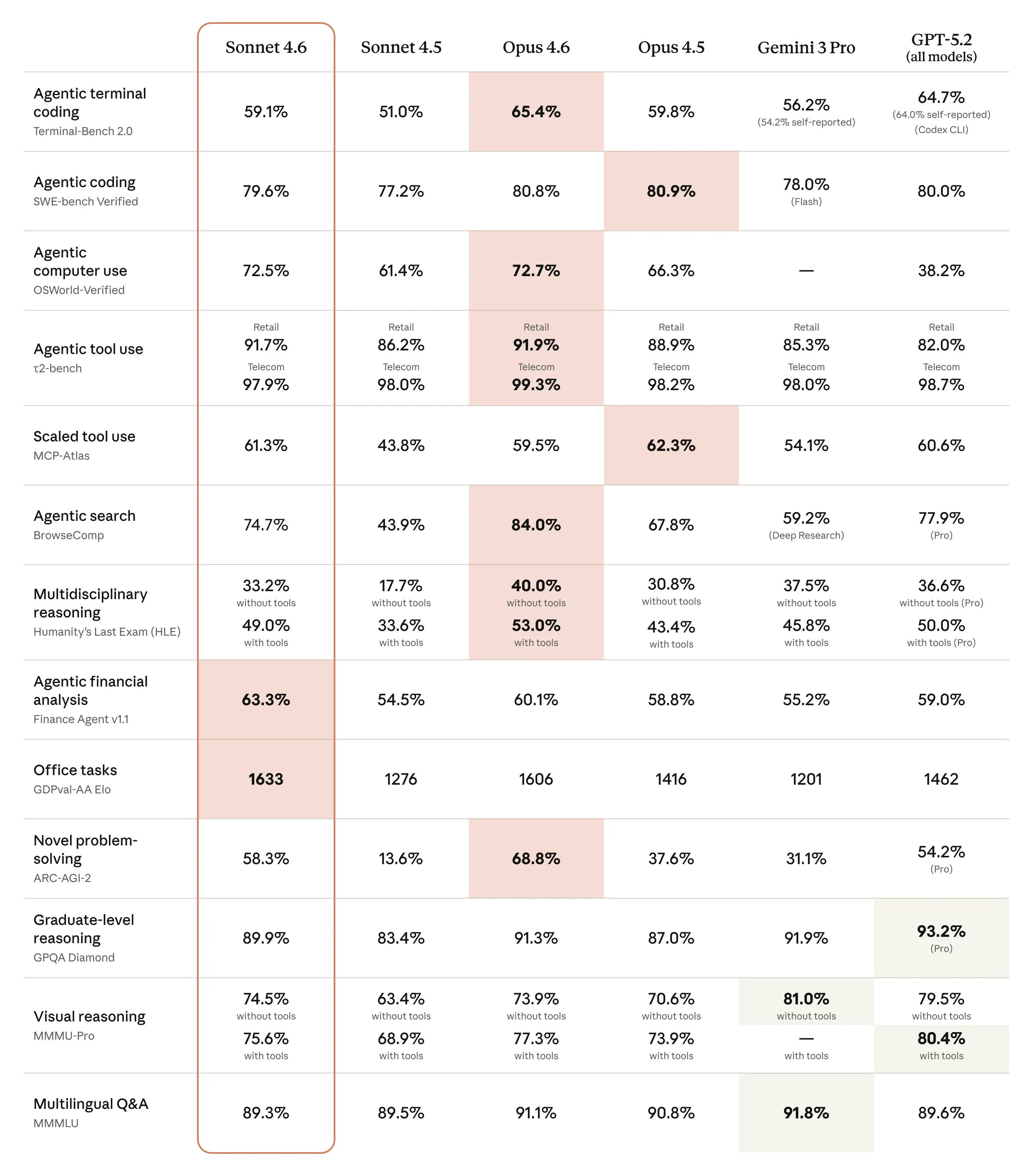
In my general use so far in chat contexts, I don’t find a major difference between Sonnet 4.6 and Opus 4.6, and I don’t plan to use it in coding contexts because I like to use the smartest coding models available to me.
So, there you have it — that’s Sonnet 4.6.
Superbench
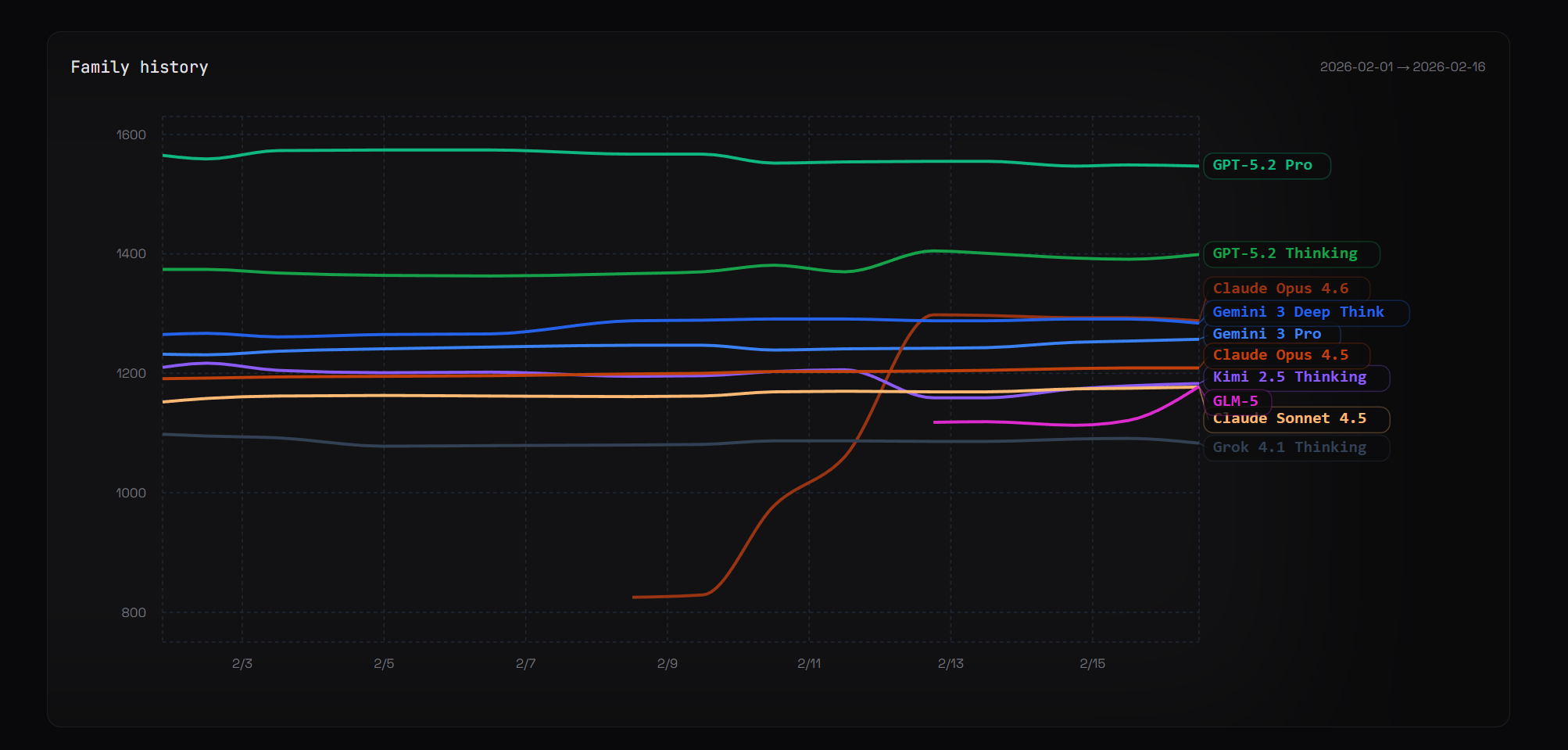
Some of you might know that I run a personal model benchmark. I send 60%+ of my prompts to multiple LLMs in their chat applications, and then stack rank the responses. I’m biased, but I think it’s the best AI benchmark on earth.
We don’t have enough data yet for Grok 4.2 or Sonnet 4.6, but I don’t expect either model to disrupt the current status quo as of February 17.
Speaking of February 17 — it’s my birthday! As a gift, it’d be incredible if you forwarded this to AI-curious or AI-nerd friends in your life, or shared on socials:
Otherwise, happy Tuesday — stay frosty out there.
Best,
Sherveen