
Anthropic says experts get better results from AI. But why?
Humans have stopped valuing expertise, but AI knows that experts still make the world go round.

Anthropic just published an analysis of ~400,000 Claude Code sessions to determine how expertise might drive better outcomes in their most agentic tool.
The headline: “Claude does more per prompt for more expert users.” An average prompt from a typical “novice session” results in roughly 5 actions and 600 words of Claude output, while an average expert session results in 12 actions and 3,200 words.
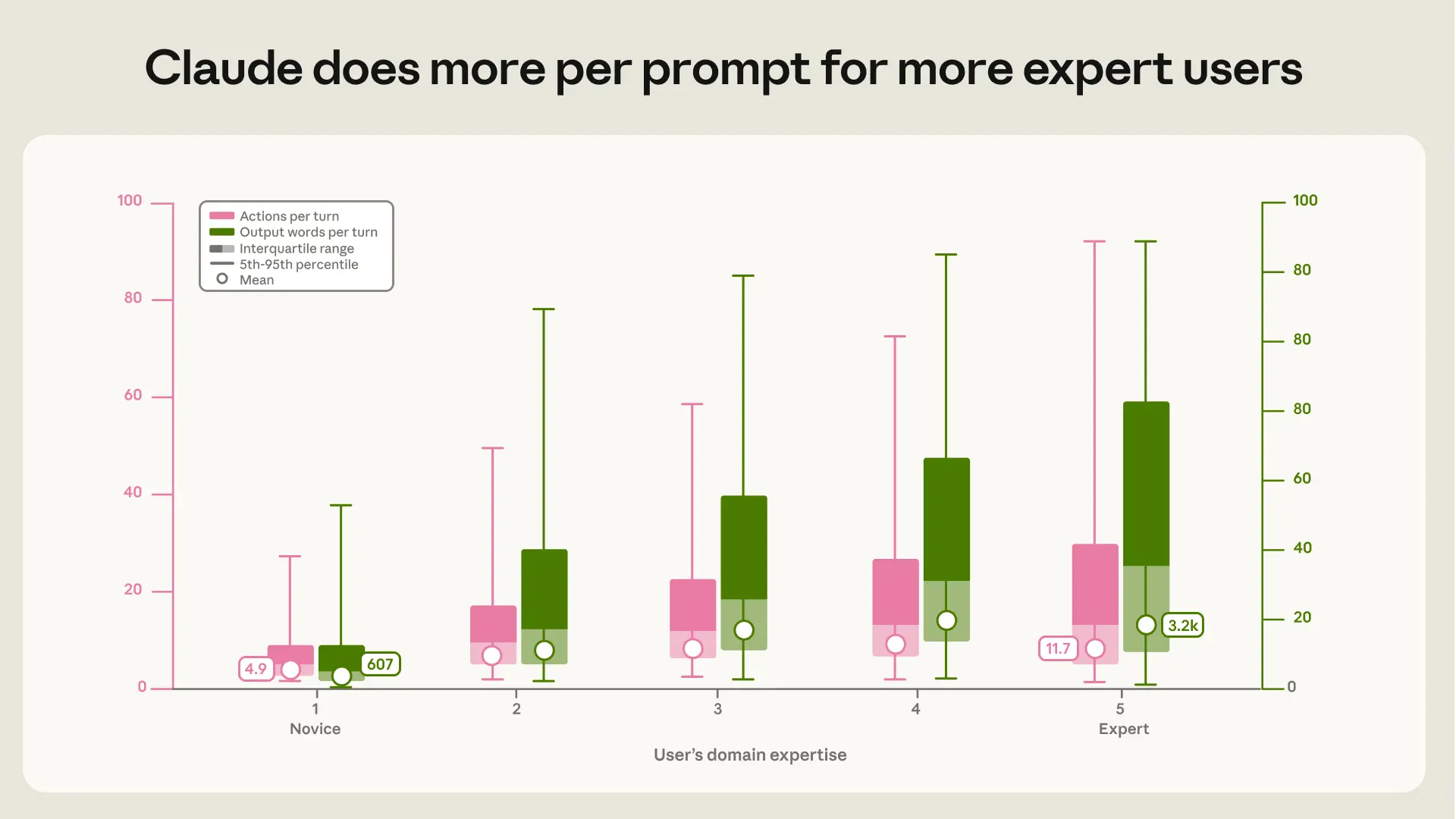
The most interesting finding, to me: this is more about any-domain expertise than specific expertise with coding agents or computer science, even when the primary activity is writing code.
In other words, many people across functional areas now use Claude Code, including those with no programming expertise, and as Anthropic put it: “In sessions that produce code, every major occupation succeeds at rates within a few points of those in software-related occupations. It appears that coding agents are making a coding background less relevant to successful programming.”
If you’re an expert, even if it’s in medicine or woodworking, you’ll have as much success (depending on your goals, of course) as software engineers.
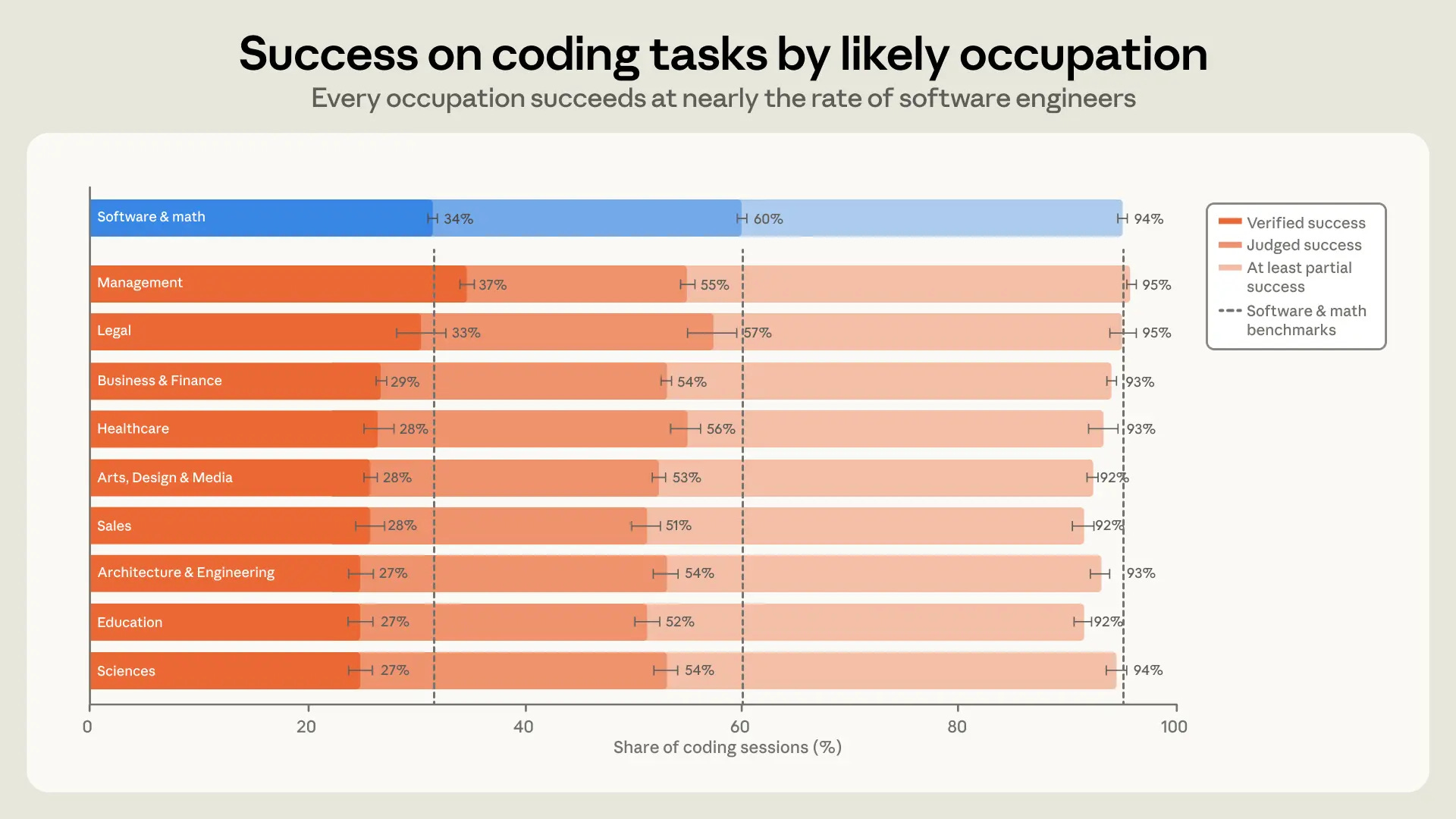
We could call this unintuitive, because we’d expect that people who know how to code can better plan technical projects, direct proper implementation, or fix mistakes. We could call this intuitive, because an expert is more likely to understand their goals, and therefore better-equipped to plan and to adjust what they want based on what they see.
In other words, a doctor who understands medicine is going to bring more context to Claude Code to build a prototype clinical tool, much more effectively than their coding background might predict. In fact, they may outperform a software engineer, even though that software engineer could contribute to the technical implementation.
A caveat: to be clear, a software engineer getting context from a doctor will still be far better suited than the doctor (or several doctors) alone, since they’d be combining their expertise from across domains. As a product gets more complicated, the need for a wide variance of expertise increases rapidly.
In either case, I found Anthropic’s nuanced explanation of the mechanics of this a helpful explicit frame: as coding agents have become more capable and autonomous, the divide between what the user does and what the agent does has morphed.
In their analysis:
On average, people make about 70% of the planning decisions but only 20% of the execution decisions. In practice, there is a clear division of labor in agentic coding –– people decide what to build, and the agent decides how to build it.
The division of labor
The execution is getting less variable. Agents are getting far better at code and self-testing without supervision. They need the human less to get the job done. But humans are still essential in defining the goal and judging the qualitative endpoint (ex. we built what I thought I wanted, but is the thing I wanted actually useful?).
And making something useful is much harder than making something that works. The variance of consequence between choices about what to build, or what the user experience should be, is much higher than the variance of consequence on if your code is 10 or 25% more efficient. (Obviously, that’s not always true -- sometimes, code efficiency is the thing itself, ex. in enterprise SaaS.)
So, the TLDR -- the expert is bringing in the expertise that Claude Code doesn’t already have: all the not-code parts. Of course, the frontier AI models are good at things like architecture or marketing, but those fields are less “programmatic” and verifiable compared to engineering, and so the loop that lets Claude know it wrote good code doesn’t exist in those other fields.
AI can tell code works because it can run a test suite on an app it made, and know that it successfully turns on. If it wants to know about the success of a marketing campaign it crafted, it’d have to wait for a few months of results to trickle in and for a human to bring back the data.
Okay, all of this was interesting enough, but does it teach us anything new we can take to our AI muscle, beyond “bring your expertise?”
Well, I think there are a variety of tactics that can help you generally prompt an LLM with more of your context, but I also wanted to break out what this tells us to do to get better results even outside of our expertise.
If expert-style steering encourages Claude to do better work…
1: Do pre-work separately from work-work
Separate your research phase from your execution phase. When you’re trying to figure out what to build (user experience) and how to build it (technical choices), even if it’s something like a complex research report or legal document, do your exploratory research work in its own session.
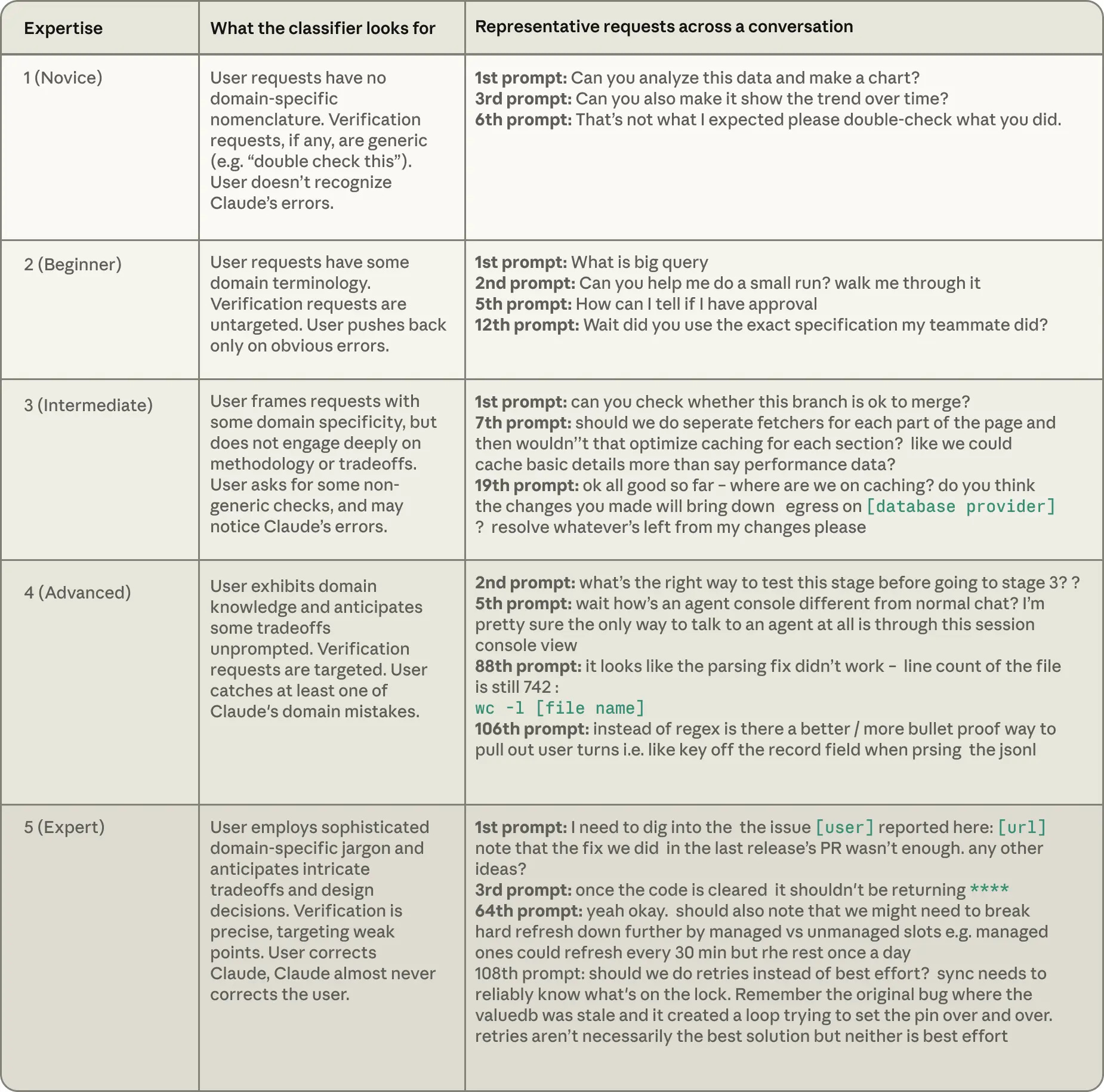
Anthropic makes the point: “the gap between novice sessions and intermediate sessions is bigger than the gap between intermediate and expert.” So, accrue the sort of context that an intermediate user would have on the subject matter, as quickly as possible. Then begin to build your project.
When in research mode, if you’re not an expert on whatever you’re doing, ask for a decision map after you get through your first few questions and ideas -- ex. “What other decisions should we make before I go work on this with an outside agent? what tradeoffs or opportunities haven’t we considered?”
Hint: If any given prompt is going to be some amount of actions and words, you want all of that response to be dedicated to one “mode” -- don’t force the agent to toggle between being a Q&A chatbot and a highly autonomous AI.
2: Improve your specifications
When requesting complex output, include caveats and assumptions. One thing that experts do constantly is “chisel” the shape of a request so that their recipient (whether a teammate or AI) doesn’t get distracted by “the obvious answer” or traps.
In the research, Anthropic points to an expert as someone who anticipates edge cases, and therefore doesn’t just ask for the happy path (“build a thing that works”) but also defines the negative space (“build a thing, but watch out for X, Y, and Z, and consider A, B, and C”).
3: Tell agents what counts as done
Be sure to define a “test suite” for judging end results. Anthropic notes that one attribute of experts is their precise requests for verification. In other words, how are you telling Claude to prove that the work is ‘right’?
This will differ in different domains, but Anthropic’s example is illustrative:
An accountant who has never used Python, but tells Claude exactly which reconciliation rules a Python script must enforce and catches the edge case it mishandles at month-end close, is an expert at that task.
By getting precise about requirements for success, you’re giving the agent more confidence to take specific and fast action toward those requirements.
Because non-code work doesn’t have the same compiler or unit test dynamics as software engineering, you’ll need to create a “synthetic” test or set of requirements so that the AI can check its own work before presenting a final answer.
So, an accountant is bringing not just their expertise, they’re also naming a few rules and an edge case to explicitly mentor the model toward what “good” looks like.
Negative space: What must not go wrong?
Proof of done: What observable evidence would show that things went right?
A caveat: something Anthropic isn’t saying in this research, and I want to warn against: none of this means “overstuff your prompts” or “do too many steps per prompt.” Sure, the average expert prompt is probably much larger than a novice one, but that’s about the density of context (aka planning decisions). When you have an agent try to do too much in one go (say, two features instead of one), and don’t properly delegate a step at a time, you’re likely to get worse results overall.
I’m excited by research that attempts to understand good “AI muscle” and helps us explain why talent and expertise might always (until… AGI?) continue to give outlier individuals an advantage in producing outlier outcomes.
Alrighty, that’s all for now.
Bring your expertise with you,
Sherveen