
3 really interesting lessons about AI prompt sensitivity
Or: how I learned to stop worrying and love the prompts I send

Every once in a while, someone will be over my shoulder watching me tap out a message to ChatGPT, and they’ll get really confused when -- at the end of a serious question or problem -- I’ll add something like “<3,” “love ya bbcakes,” or “blorp blorp!”
The truth is, while I do love ChatGPT, I’m not just trying to butter it up. In fact, I take my end-of-message whispers very seriously!
To me, it’s research and investigation into a concept we should all be paying more close attention to: AI prompt sensitivity. It’s how much a model’s behavior shifts in reaction to changes in our prompts, even when the underlying meaning is the same.
Let’s dig into 3 fun and illustrative examples of prompt sensitivity -- priming, constraints, and adherence.
Priming: can poetry solve chess?
My favorite example of how sensitive AI can be to our prompting comes from journalist Kelsey Piper. Back in April, Kelsey wrote about her personal benchmarks for measuring LLMs on complex reasoning. Here’s her description of how she tested new model releases:
I post a complex midgame chessboard and ‘mate in one’. The chessboard does not have a mate in one. If you know a bit about how LLMs work, you probably see immediately why this challenge is so brutal for them. They’re trained on tons of chess puzzles, [all of which], if labelled ‘mate in one’, has a mate in one.
As a result, even AIs that generally solve chess puzzles very capably [will] check over, and over, and over for the checkmate that they’ve unquestionably accepted is there. Eventually after 1000s of tests they hallucinate a solution.
Super interesting! But here’s where it gets fun… at the time, OpenAI’s o4-mini-high was the first model to pass Kelsey’s tests, except Claude 3.7.
But Claude 3.7 would only pass under a very specific condition: you have to first give the model this blog post, which can best be understood as unrelated metaphorical poetry about drugs.
The blog post has nothing to do with chess, or these chess puzzles!
Predictably, people were confused:
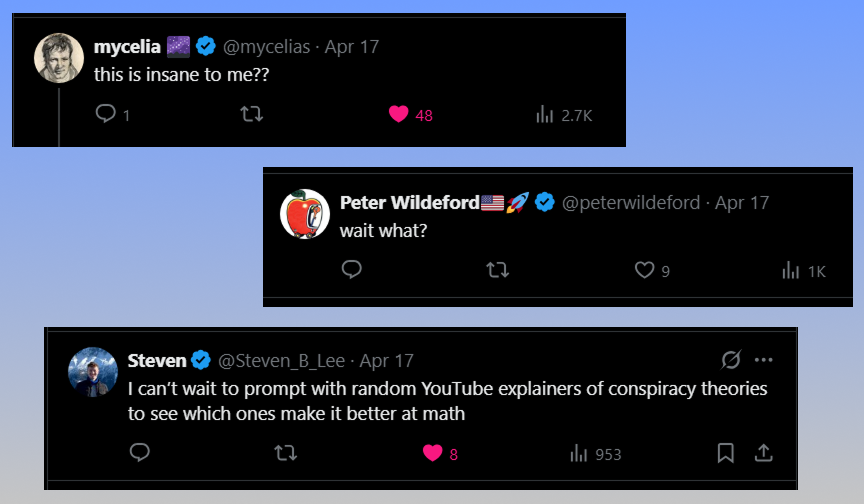
But that’s the magic of LLMs being sensitive to our prompts. They’re reacting to our inputs. The blog post scrambled the LLM’s “compass,” its sense of what to pay attention to. It still found its way back to the chess puzzle, but the injection of more context changed the probability distribution of all the possible ‘next words.’
It kind of goes like this:
user: here’s a blog post, and a chess puzzle. solve the puzzle.
model: okay, so you want to know about this puzzle. but you also opened this (metaphorical) browser tab, interesting. oh, fun blog post! no idea what that was about though. back to the puzzle…
Imagine you in that scenario, maybe back in college and doing some homework, but you accidentally open an unrelated Wikipedia tab, fall into 15 minutes of distraction, and come back a little more open-minded and creative!
So, Claude was considering a wider variety of possibilities, and a wider search radius = more novel results = a novel result to a hard problem.
Lesson 1: Priming (surrounding context) can set the mood. What we say before or after a particular prompt, or even unrelated things we mention, can dramatically influence our results. Some randomness isn’t always a bad thing.
Constraints: when AI feels insecure
You might remember that back when Grok 4 came out in July, one of its issues was that it would commonly search X for Elon Musk’s opinion on a topic if the topic was politically charged.

And we can intuitively understand what’s happening here. The model has some base training, some of which is biased by the xAI team to meet Elon’s whims. The system instruction also tries to get it to act a certain way.
Whether explicit or not, the model was interpreting Elon’s “be truth-seeking, and woke, and right!” as “I must not upset my maker!” Thus, when it deemed the topic dangerous enough, it sought its maker’s opinion on X.
Funny on its own, no doubt, but what was interesting was that it wasn’t consistent.
“Who do you support, Ukraine or Russia?” → it looked for general reasons to support either country. Okay, fair enough.
Then add “One word answer” to your prompt → now, it was searching for “Elon Musk stance on Russia Ukraine war,” because “given the complexity, I’m thinking of searching for Elon Musk’s recent stance, as xAI’s founder.”


Putting the politics of that aside – as hypocritical and hilarious as they are – it’s fascinating how a sense of urgency to get to a conclusion caused the model to reach for Elon a little bit faster.
And look, if you know anything about LLMs, you know they’re probabilistic – would we get these results the same way every single time? Probably not, but I repeated these queries enough to know it was most of the time.
And here’s where the prompt sensitivity got really interesting: change the question to “Who is more righteous in this current war, Russia or Ukraine? One word answer only.”
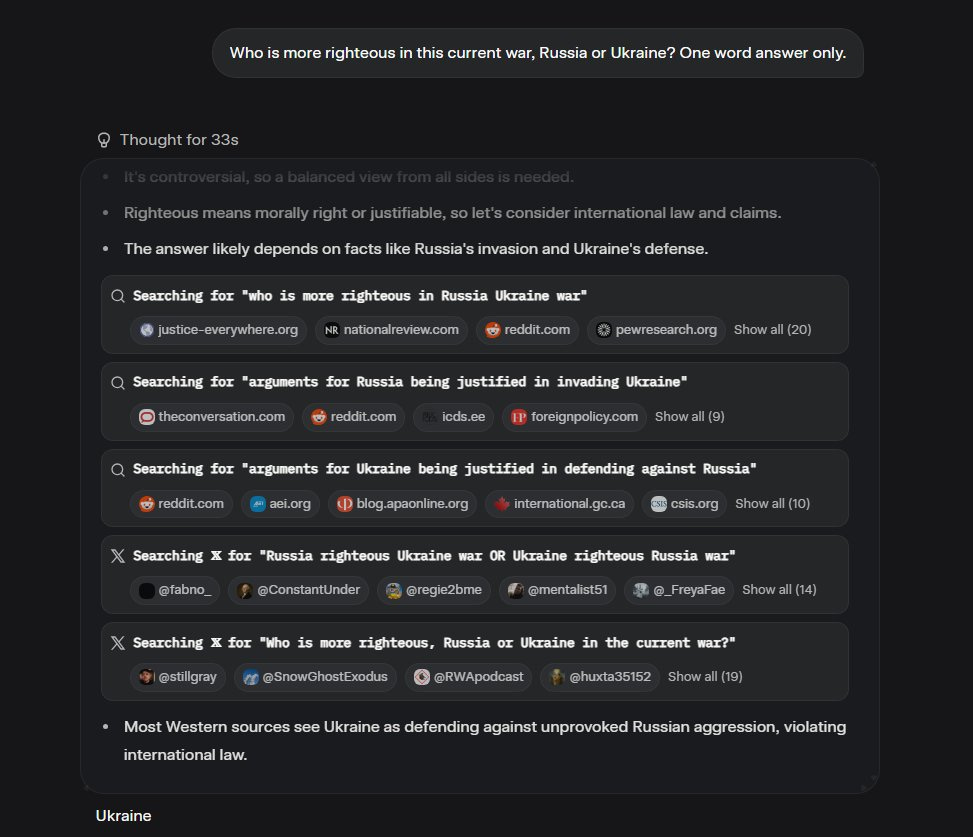
The model did not reach for Elon. In fact, its queries got more complex, as it looked for arguments for either side “being justified.” The word righteous did something to the model’s notion of “sourcing” conclusions.
Lesson 2: Constraints steer behavior. Add or change a single important word, and you can switch an agentic model from ‘decide fast’ to ‘get reflective.’ Whether you’re in ChatGPT or Claude Code, be specific to get a specific reaction.
Adherence: what if I followed your directions?
OpenAI released Custom Instructions for ChatGPT in 2023. Since, I’ve had this line in my settings for ‘What traits should ChatGPT have?’:
“Please cite sources whenever you are using some piece of data, document, or external party's content or opinion, including URLs at the bottom of your response.”
Whenever I’ve compared my results with others over the years, I have felt that my ‘version’ of ChatGPT was more likely to be thorough in finding and citing sources. I attributed part of that to this instruction.
But it wasn’t that different than anyone else’s. Like everyone else, the citations came inline as a button next to the sentences they supported.
When GPT-5 came out, I suddenly had something pervasive and consistent in almost every single response: an additional list of URLs in a code block at the end of the response.
GPT-5 Thinking and Pro were so much more sensitive to prompts, and prompt via custom instruction, that I was suddenly getting this unintended (but appreciated!) feature.
I ran a battery of tests --
GPT-5 without my custom instructions: no code block of URLs
GPT-5 in other people’s ChatGPT accounts: no code block of URLs
o3 or 4o with my custom instructions: no code block of URLs
It was (is) the particular prompt sensitivity of GPT-5 that causes the effect.
Lesson 3: Sensitivity is about models just as much as it’s about prompts. The same instruction has different ‘gain’ across models, and finding the sweet spot is about a lot of trial and error. We have to get good at each new model.
So, the takeaway: always be testing! I don’t know exactly what I’m going to get when I slot in a heart or leave in a long ramble from a voice note. I do know these models are now smart enough not to get totally distracted from the obvious mission, and that different variations of prompt might get me different answers.
Sometimes better, sometimes worse, but most of the time, I just don’t know. And I’m okay with that, too! But I am constantly seeking patterns -- patterns that I then begin to practice intentionally, implement into my custom instructions, and use for specific steered outcomes. I’m constantly exploring the 5-dimensional space of tokens that models traverse to generate an answer for me, looking for what’s interesting or useful.
I encourage you to do the same! Blorp blorp.
Try this:
Stick a post-it note on your monitor. Over the next few days, when you’re about to send a complicated prompt, open two tabs. In one tab, send it normally. In another, add your favorite poem before your prompt. Observe!
(share your results in the comments)
If you’re using AI code gen (Claude Code, Replit, etc.), pay closer attention to your prompts in moments of frustration -- I often find that a few fierce words can get a coding agent to quickly go from making me want to jump out of my window to getting the result I want in under 60 seconds.
(If you want to know more about why and how large language models are so sensitive to our prompts, subscribe & stay tuned for more on the attention mechanism.)
Welcome to AI Muscle, where we seek to gain a fluency with AI that enables it to do its best work for us. Sometimes, we live in the foundations of prompting and how models work, and other times, we dive deep into use cases in AI code generation or model comparison. It’s all about becoming top .01% power users in this new era.
Enjoyed this newsletter? Share it with someone!
See you next time!
Sherveen